Fra kaos til superkrefter: Strukturert innhold forklart på fem nivåer



Vilde Serina Partapuoli

Du har nettopp flyttet til en ny by, og din 9 år gamle datter vil låne Harry Potter-bøkene. Enkelt nok, tenker du – det er jo bare å stikke innom biblioteket.
Men dette biblioteket er annerledes. Det er verdens verste bibliotek.


Bøker, magasiner, CD-er ligger strødd utover gulvet. Kokebøker står stablet oppå krimromaner, som igjen er blandet med gamle IKEA-kataloger og en og annen finsk tegneserie. Det finnes ingen avdelinger. Ingen kategorier. Ingen skilt. Ingen system. Bare kaos.
Du må ha hjelp. Etter mye leting finner du til slutt en livstrøtt bibliotekar som graver i en haugene.
«Jeg skulle hatt den første Harry Potter boka, hvor finner jeg den?»
«Aner ikke» mumler han, mens han er demotivert prøver å sortere en bunke bøker etter fargen fargen på omslaget. «Tror jeg så en med drage på coveret borte ved hage-seksjonen i går.»
Etter førti minutter leting gir du opp, går hjem og kjøper bøkene på nettet i stedet.
Høres ut som et mareritt, sant?
Vil du høre noe som er enda verre? De fleste nettsider er bygget opp på samme måte som dette grusomme biblioteket.
Det forårsaker enorme mengde tapte timer og unødvendig energi som vi alle kunne brukt til bedre ting.
Og motsatt: De som har tatt seg bryet av å strukturere informasjonen? De går inn i fremtiden med superkrefter.
Biblioteker viser strukturert innhold i praksis
La oss gå tilbake til biblioteket. Men denne gangen, et ordentlig bibliotek.
Interiøret
Når du går inn på nesten hvilket som helst bibliotek i verden og leter etter Harry Potter-bøkene, så finner du dem relativt enkelt. Hvorfor? Fordi biblioteker følger et forutsigbart system.
Bøkene er organisert i avdelinger. Barnebøker her, voksenlitteratur der, faglitteratur et annet sted. Innenfor hver avdeling finnes det ofte underkategorier: fantasy, krim, biografier. Og innenfor disse kategoriene er bøkene sortert alfabetisk eller etter forfatter.
Du vet hva du leter etter – "Harry Potter og de vises stein" av J.K. Rowling – og systemet hjelper deg å finne det.
Databasen
Alle biblioteker har dessuten et datasystem alle bøkene i en stor database – kategorisert på mange av de samme måtene.
Det er som regel superenkelt å finne alle bøkene av en spesifikk forfatter, hente ut alle bøker innenfor et visst tema, få ut statistikk på hvilke bøker som er mest populære… Og mye mer mer.
Men systemet kan også kategorisere mer enn bare bøker. Og det er som regel løsninger for å knytte ulike utgaver, oversettelser og formater til samme boka.
Bibliotekaren
Med disse verkøyene på plass får bibliotekaren superkrefter. På få sekunder kan bibliotekaren vise vei, og når bøker skal settes på plass vet han nøyaktig hvor den skal, så nestemann finner den.
Istedenfor å bruke hele dagen på å lete, kan de heller være eksperter på sitt fagfelt, anbefale gode bøker – og hjelpe til med mye mer enn å bare finne frem bøker.
Fordelene er tydelige
Hele denne scenen viser strukturert innhold i praksis.
Man har laget et forutsigbart system som gjøre lett for både mennesker og roboter å:
- Finne fram raskt til informasjonen man er ute etter
- Se annen relatert informasjon som kan være nyttig
- Behandle informasjonen for å få ut det du vil (f.eks. statistikk)
- Gjenbruke informasjonen på helt nye måter.
Ikke minst frigjør det enormt mye tid og energi for bibliotekaren, som kan bruke tiden sin på mye bedre måter enn å lete gjennom systemer.
Men det er så ufattelig mye mer!
Denne artikkelen handler om å vise alle de enorme superkreftene som strukturert innhold kan låse opp.
Vi begynner med den helt enkle forklaringen, før vi tenker større og større om mulighetene.
Nivå 1: Informasjon organisert i en tabell
Du vet sikkert hvordan en database fungerer, men la oss begynne der likevel.
Forenklet sagt, så kan du se for deg at alle bøkene er organisert i et tabell i et excel ark, som dette:

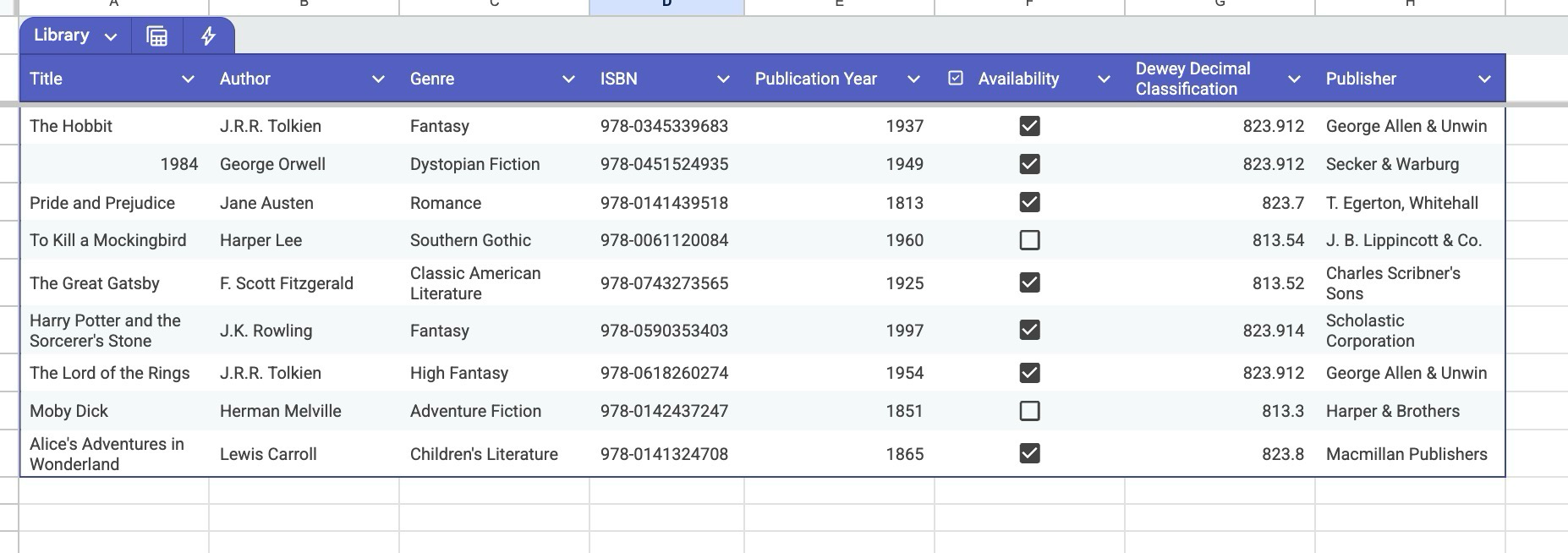
Det gjør at jeg enkelt kan filtrere ut akkurat de bøkene som passer mine kriterier. Jeg kan gjøre ulike "spørringer" på innholdet. For eksempel:
- Gi meg alle bøker publisert etter 1960 som er utleid i sjangeren “Fantasy”.
- Gi meg alle bøker som starter på “F” og er publisert av Scholastic.
Men selv med denne begrensede informasjonen kan du gjøre mer enn å bare finne bøker. Du kan også:
- Føre statistikk på hvilke bøker, sjangere eller forfattere som er mest populære
- Finne morsomme mønstere i titlene: Er det noen ord eller bokstaver som er mer populære enn andre en visse sjangere?
- Se historisk når en forfatter eller sjanger var mest aktive.
Merk deg at allerede her er det åpenbart at strukturert innhold kan være nyttig. Likevel er det bare starten…


Nivå 2: Ulike typer informasjon kobles sammen
I forrige runde var bøkene i fokus. En rad i regnearket tilsvarte en bok.
Vi kan gjøre akkurat det samme for sjangre og forfattere, og gi de hver sin "tabell".
En for sjangre: Med beskrivelser, karakteristiske elementer, viktige forfattere og bøker
En for forfattere: Med navn, beskrivelse, nasjonalitet, år de er født og døde, sjangere.

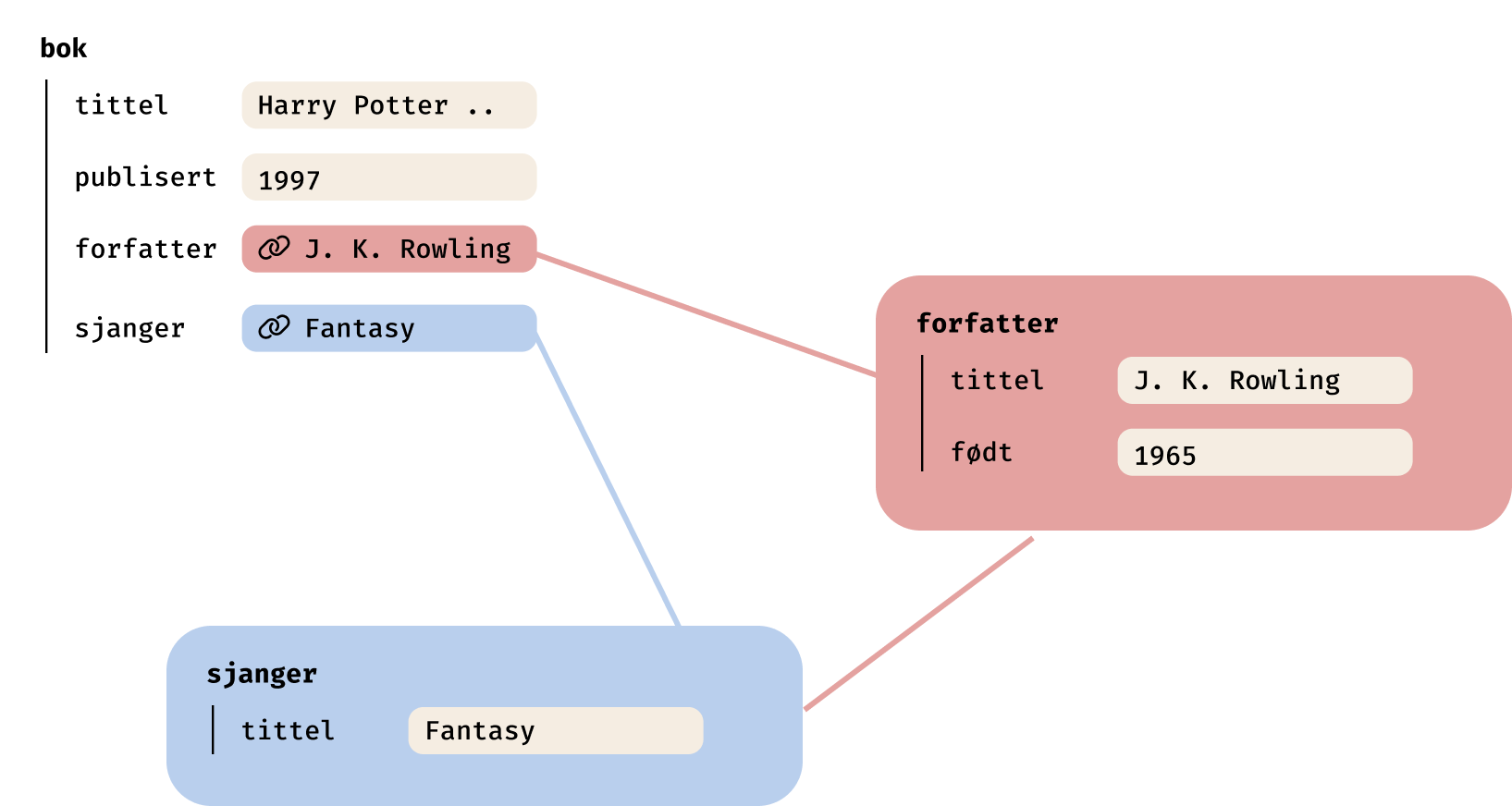
Magien oppstår når vi kobler informasjon sammen
Der informasjonen som før ble skrevet inn i regnearket som ren tekst, så er en forfatter nå heller en referanse et annet sted der informasjonen bor.
Tenk på det sånn her:
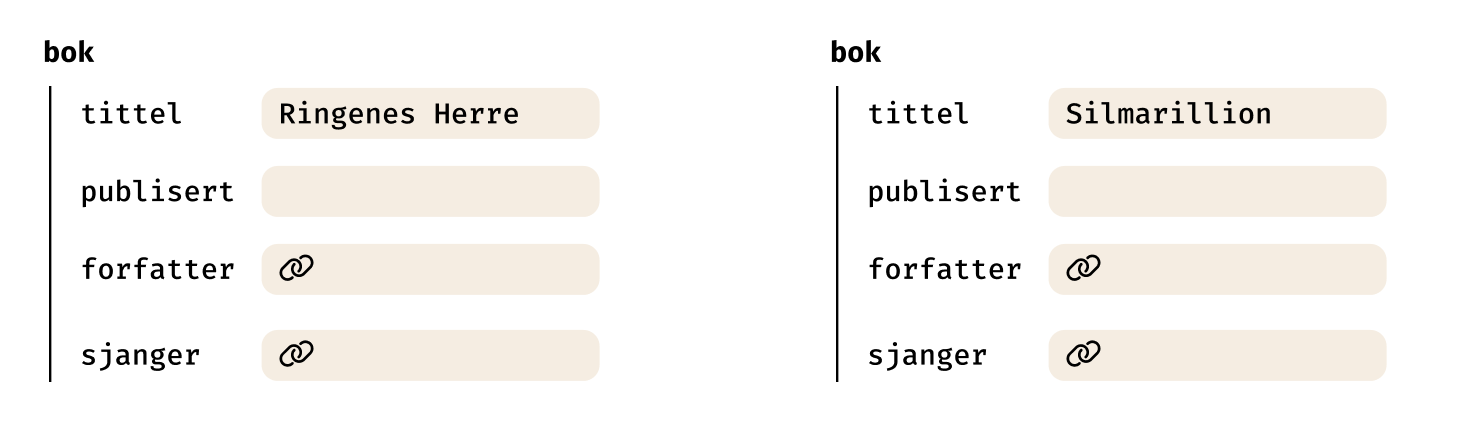
Hvis du går inn på en Wikipedia-artikkel om Ringenes Herre, vil du ganske raskt se en lenke til Wikipedia-artikkelen J.R.R. Tolkien. Når du trykker deg inn på J.R.R. Tolkien vil du se mer informasjon om han.
Så informasjonen om J.R.R. Tolkien “bor” på hans egen Wikipedia-artikkel. Og Ringenes Herre-artikkelen refererer til denne gjennom en lenke.

Informasjon som er koblet sammen låser opp enorme fordeler i hverdagen
Når vi koblet sammen innhold så oppstår det enormt mange fordeler.

Raskere å legge inn mer informasjon
Tenk deg en person som legger til en ny bok i bibliotek-systemet. Istedenfor at de manuelt må skrive inn forfatteren og all informasjon om dem, så kan de legge til en referanse til forfatteren. Vipps så er riktig forfatter registrert, med tilhørende informasjon.
Ikke minst så gir strukturen tydelige rammer til den som skal legge inn innhold. Istedenfor at du starter på blanke ark – med full frihet, får den som legger inn innhold tydelige retningslinjer på hva som skal puttes inn i systemet.

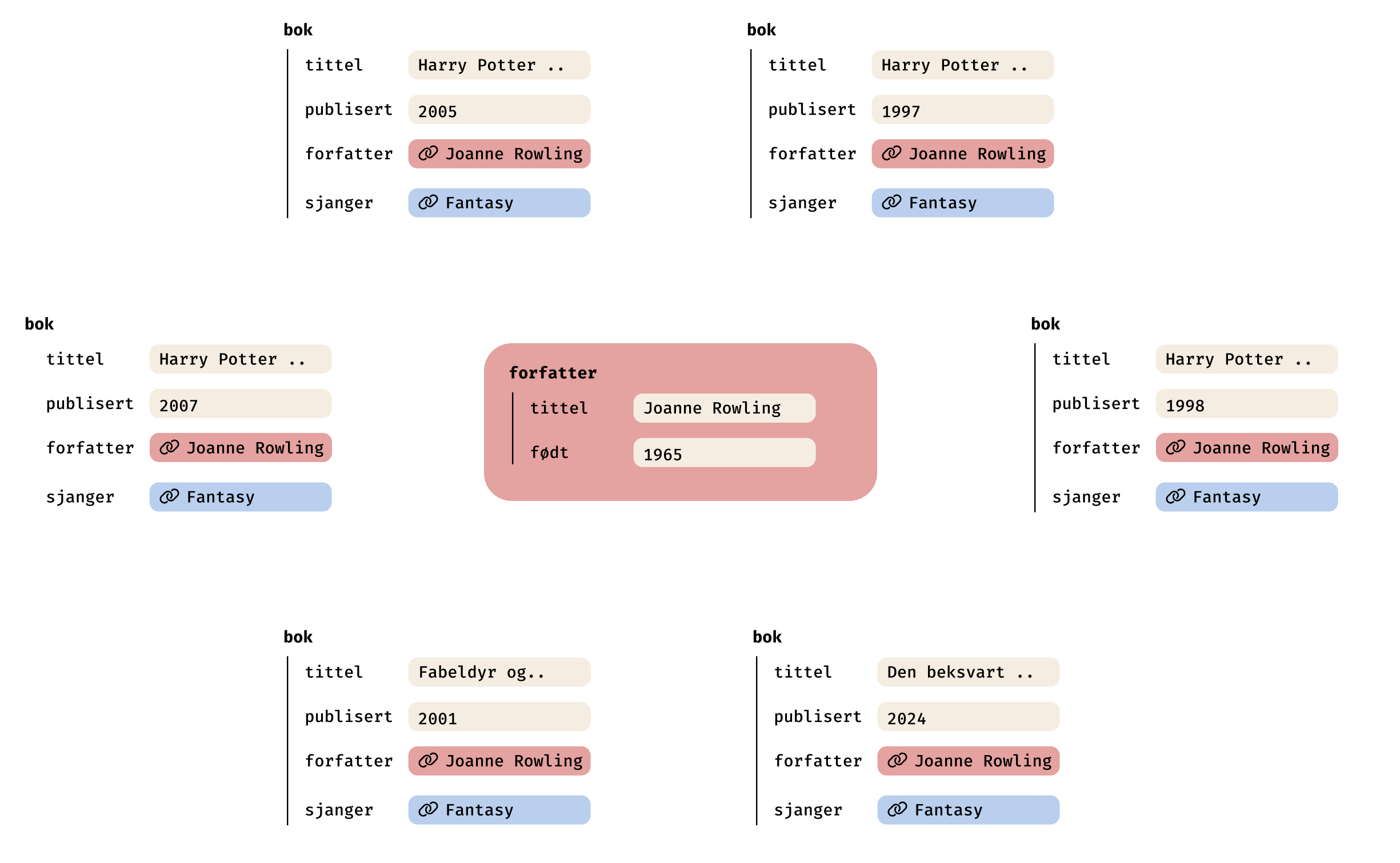
Informasjonen endres ett sted
Se for deg at en forfatter endrer navn. I et system der informasjonen ikke er koblet sammen, betyr det at en eller annen må ta ansvar for å manuelt gå gjennom ALLE stedene hvor denne informasjonen listes opp.
Men om innholdet ditt er strukturert på en smart måte – så kan du enkelt nok endre dette ett sted – og så vil alt oppdateres automatisk.

Lettere å se relatert innhold
Når vi lagrer informasjonen på denne måten, oppstår det enormt mange nye bruksområder. Et av de viktigste er hvordan det blir enklere å utforske og finne fram til relatert informasjon.
Hvis 9-åringen din likte Harry Potter, så kan vår nye innholdsstruktur nå gjøre det veldig mye enklere å:
- Finne flere bøker av samme forfatter
- Finne andre fantasibøker utgitt på samme tid
- Finne andre bøker som deler karakteristikker med Harry Potter
- Og mye mer.

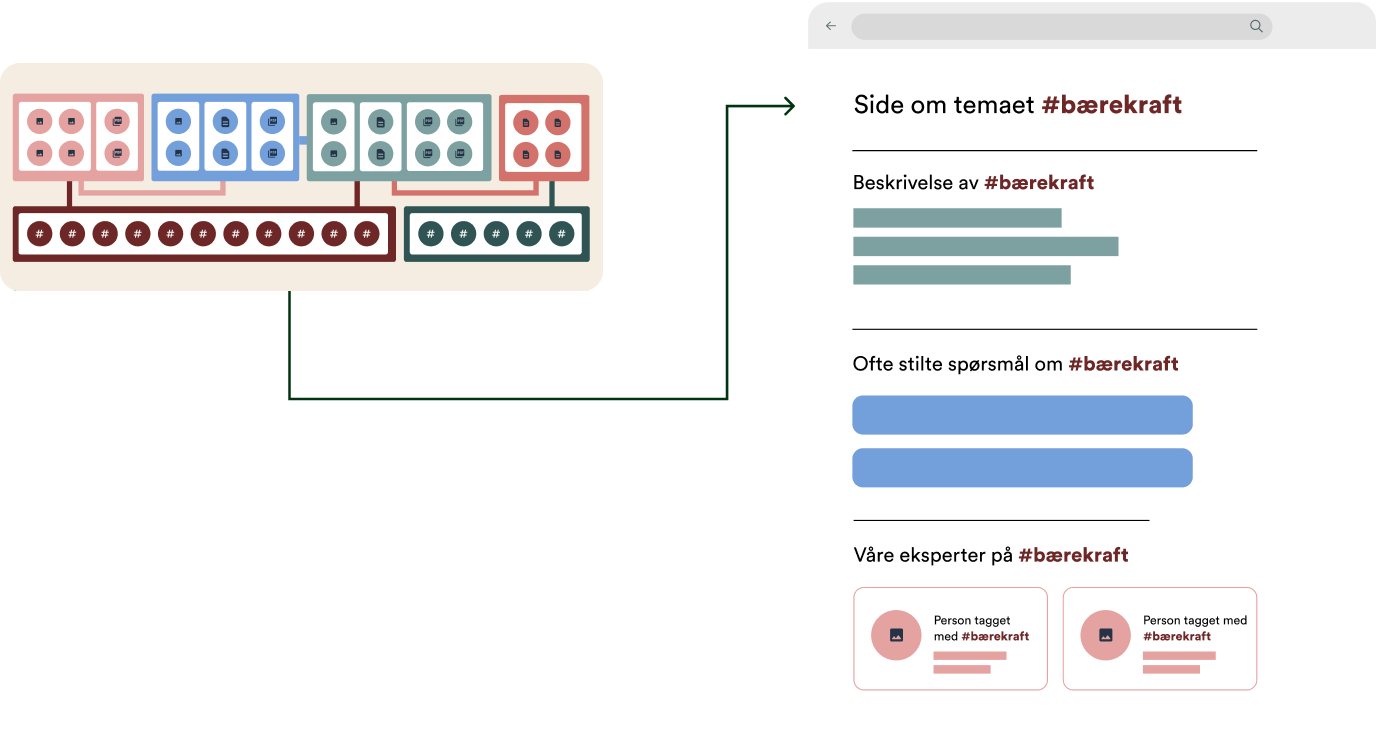
Innhold kan gjenbrukes på nye måter
Se for du jobber i kommunen, og får en idé til til en egen leseapp for barna.
Du forteller om idéen til barna, naboer, politikere og biblioteket – og alle er superengasjert. Dette må vi gjøre!
😡 Men så kommer din kollega Roger inn med en kritisk stemme inn fra siden:
For at den skal være nyttig, så må det jo ligge ti tusenvis av bøker der inne. Hvem er av oss skal gjøre det!? Jeg har ikke tid.
Men vent? Dette er jo ikke noe problem. 😎
Det er her du kan briljere med dine kunnskaper om strukturert innhold.
Du forklarer at dere selvfølgelig ikke trenger å gjøre alt på nytt. Dere kan jo bare hente innholdet direkte fra databasen til biblioteket.
Som igjen henter innholdet sitt fra et annet sted – der det alltid holdes oppdatert.
Roger er sjokkert over nytteverdien til strukturert innhold, og ytrer aldri et negativt ord igjen. Hurra!

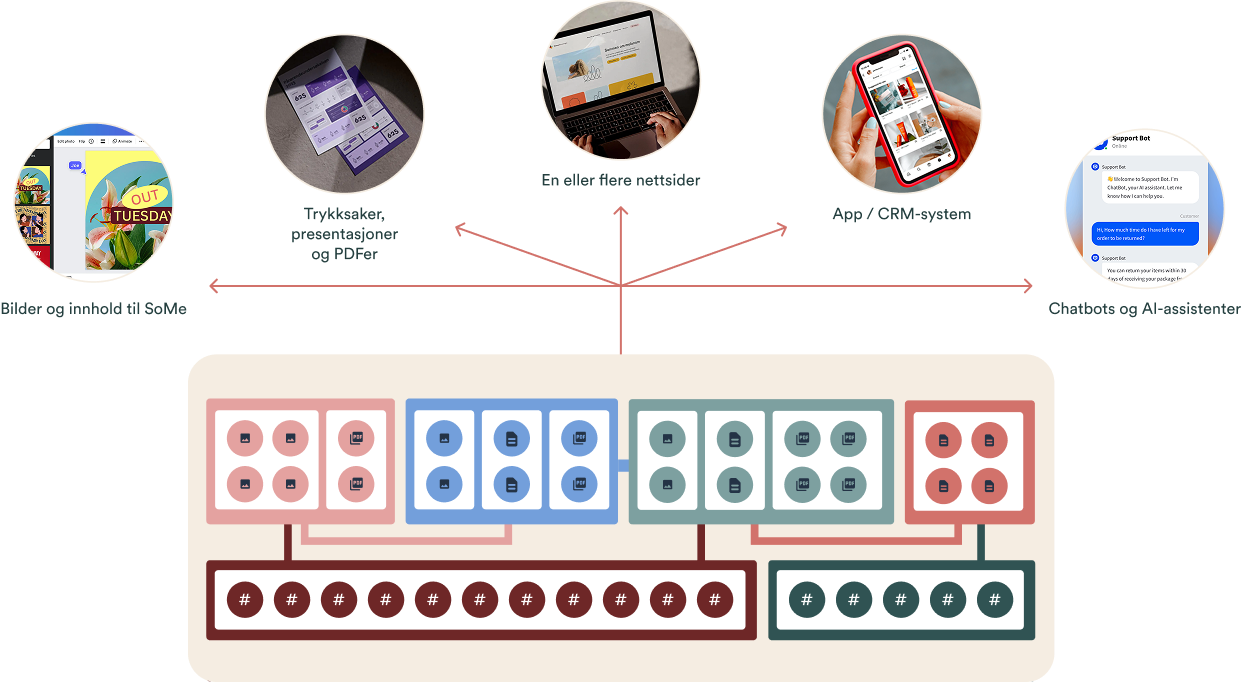
Bare fantasien setter grenser for hva strukturert innhold kan gjenbrukes til
Når du tenker over det, så kan innholdet fra biblioteket gjenbrukes på utallige smarte måter:
- Nye apper, kampanjesider, interne verktøy. Hvis dere får en god idé til noe som kan løse et problem, så er den viktigste jobben allerede gjort.
- Istedenfor å manuelt skrive inn all informasjon om en bok og laste opp et bilde hver gang du skal nevne den i en artikkel eller i et nyhetsbrev, så kan du enkelt nok bare referere til den. Vipps, så er den der! Alltid oppdatert.
Men det gjelder jo selvfølgelig ikke bare biblioteket. Alle som har en database med nyttig strukturert innhold kan gjenbruke det.
For å ta noen eksempler som vi har gjort for kundene våre:
- Gjenbruke innhold fra artikler til å lage et semi-automatisk nyhetsbrev
- Gjenbruke bilder fra mediabanken på nettsiden til å lage bilder til sosiale medier
- Gjenbruke liste med medlemmer til å lage en skreddersydd CRM-løsning
- Gjenbruke innhold fra tidligere søknader, til å lage nye søknader
Alt dette og mye mye mer – helt uten å kaste bort massevis av tid på å manuelt lete fram informasjon, copy-paste de mellom systemer og irritere seg grenseløst den dagen man må oppdatere noe informasjon.


Nivå 3: Et stort innholdsunivers med innhold krysskoblet – som åpner enorme superkrefter
Innholdsuniverset kan bare bli større og større. Når du tenker deg om kan jo egentlig alt av informasjon struktureres på en forutsigbar måte.
Jo lengre tid det går, jo mer verdifullt innhold har du og jo større gevinst blir det. Enten du jobber med å løse store tidstyver eller vil gjøre tilby en tjeneste som ingen andre kan.


Kunnskap er makt. Det samme er strukturert innhold.
Det er mange mennesker som i bunn og grunn lever av å selge store mengder med strukturert innhold.
Og folk vil kjøpe det. Med god grunn.
Hackere jobber konstant for å hente ut store databaser med kontoinformasjon og passord til ulike tjenester – som deretter kan selges igjen til de som vil ha seg et billig Netflix-abonnement, eller de som vil lure deg trill rundt.
Selv uten passord er personopplysninger om deg og meg nyttige for selgere, svindlere, eller folk som vil bruke informasjonen på helt andre måter.
Men det finnes også mer positive eksempler:
- Forskningsdatabaser som samler vitenskapelige artikler og funn på tvers av institusjoner og landegrenser
- Matvareprodusenter som strukturerer informasjon om ingredienser, allergener og næringsinnhold
- Kulturinstitusjoner som digitaliserer og strukturerer historiske arkiver, gjør dem søkbare og tilgjengelige for allmennheten
- Offentlige etater som strukturerer informasjon om lover, forskrifter og tjenester for å gjøre dem mer tilgjengelige for innbyggerne
I alle disse tilfellene skaper strukturert innhold enorm verdi – både for de som eier informasjonen og for de som bruker den til daglig.
Tenk på hva det ville betydd for din bedrift, organisasjon – om dere har strukturert all informasjon som er nyttig for dere på en plass? Hva kan dere bruke den til?


Strukturert innhold kan brukes til bygge fantastiske eller avhengigsskapende brukeropplevelser
Hvordan fikk tech-gigantene så mye makt? Vel, takket strukturert innhold.
Hver gang du går inn på Instagram, Facebook eller TikTok, så lagres det masse informasjon om deg, inn i deres gigantiske database. Hvor lenge du så på akkurat den videoen, hvem du er er mest interessert i, hvilke reklamer du trykker på.
Lik det eller ikke: Ingen kan betvile kraften i informasjonen de sitter med på oss – og hvordan det brukes på godt og vondt.
Men det kan også brukes på hyggeligere måter:
- Skikkelige gode anbefalinger som inspirerer barn til å lese
- Bli eksponert for ny musikk du vil like i Spotify
- Få nyttig informasjon du lurer på presentert for deg, istedenfor at du må bruke evig lang tid på å lete etter den.
- …


Statistikk som gir deg krefter til å se inn i fremtiden
Med mindre du er en skikkelig datanerd, er det kanskje ikke så spennende å vite hvor mange bøker som starter på bokstaven “F”.
Men statistikk kan brukes til så mange. Ikke bare til å lære av fortiden – men også til å spå fremtiden.
Tenk på det slik: Når du har strukturert innhold om hvilke bøker som lånes ut, hvem som låner dem, og når de lånes ut, kan du begynne å se mønstre.
Du kan forutsi hvilke bøker som kommer til å være populære neste sommer, hvilke sjangre som er på vei opp, og hvilke forfattere som snart vil slå gjennom.
Biblioteket kan bestille flere eksemplarer av bøker de vet vil bli etterspurt, arrangere tematiske utstillinger som treffer tidsånden, og til og med gi forfattere og forlag verdifull innsikt i hva leserne faktisk vil ha.
Dette er ikke bare nyttig for biblioteket – det er en superkraft for alle som jobber med innhold og informasjon.
Spørsmålet er: Hvilken del av fremtiden vil du se inn i?
- Hvilke produkter nettbutikken din bør satse på?
- Hvilke aksjer det er lurt å satse på?
- Hvilke bedrifter og mennesketyper som kommer til å være mest interessert i å kjøpe tjenestene dine?
- Hvordan du bør formulere en kampanje, et tilbud, en skoleoppgave for å overbevise?
- Hvilke tiltak kommunen bør investere i?
- Hva som kommer til å gjøre de ansatte glad og fornøyd?
- Hva slags klimatiltak som faktisk kommer til å fungere?


Nivå 4: Hvordan kunstig intelligens faktisk blir nyttig – selv uten en massiv database
Smarte algoritmer, store datasett og kunstig intelligens har vi hatt lenge.
Den virkelig store revolusjonen som snur alt på hodet – er språkmodellenes inntog.
Statisikk strukturert for maskiner
Det vi kaller “kunstig intelligens” er på mange måter egentlig bare statikk på speed.
Eller innhold som er strukturert på en måte som gjør det ekstremt lett for en maskin å forstå et sett med innhold.
Informasjon som ikke bare lagret i tabeller og tekst – men som tallverdier
Hvis en forsker gjør et eksperiment, så vil gjerne resultatene dokumenteres i et regneark eller en database. Som “strukturert innhold” med andre ord.
Når en AI-modell trenes opp, så kan man også si at det den dokumenter det den lærer som "strukturert innhold". Men ikke på den måten vi er vant til i hverdagen.
For AI-modeller opererer ikke med tabeller, tekst og "vanlige" tall.
I stedet lagres informasjonen som tallverdier og “embeddings” – vektorer som fanger opp betydningen i dataene.
Eksempel: Mønstere og konsepter mer enn “ord”
Forenklet sagt kan man si at at et konsept som “Harry Potter” ikke lagres som bokstavene “H-a-r-r-y” i en eller annen database.
Istedenfor lagres "Harry Potter" som en egen unik tallverdi (eller "embedding").

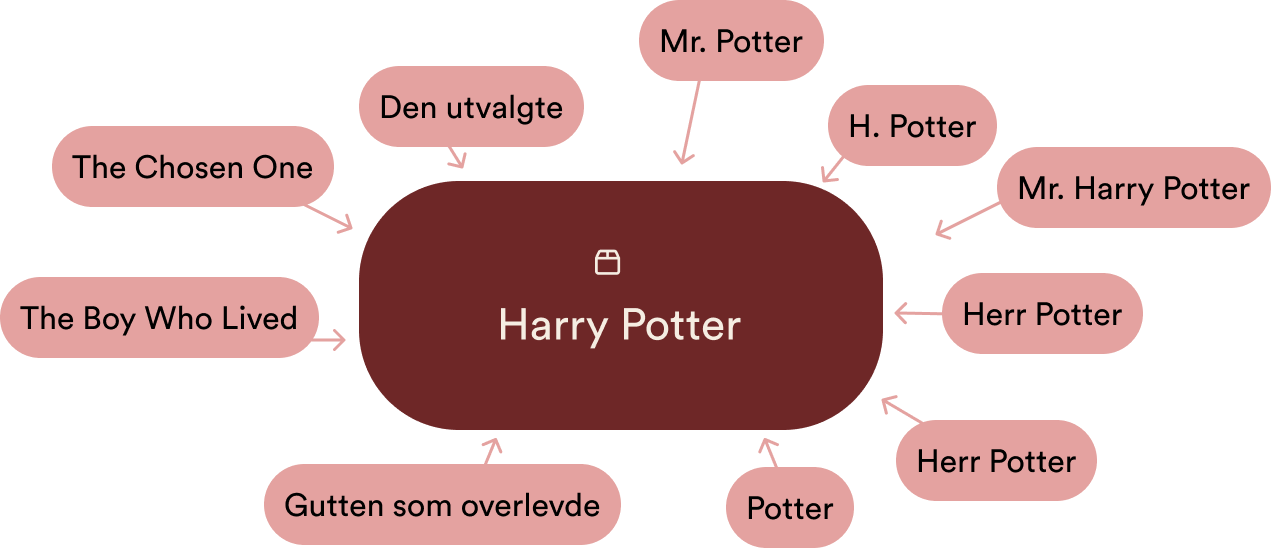
Andre konsepter, kallenavn, hva en du kalle det – assosieres til "Harry Potter".
Det dette som gjør at Google og andre søkemotorer kan foreslå: "Mente du Harry Potter?" når du ved et uhell søker på "Hrry Potter".

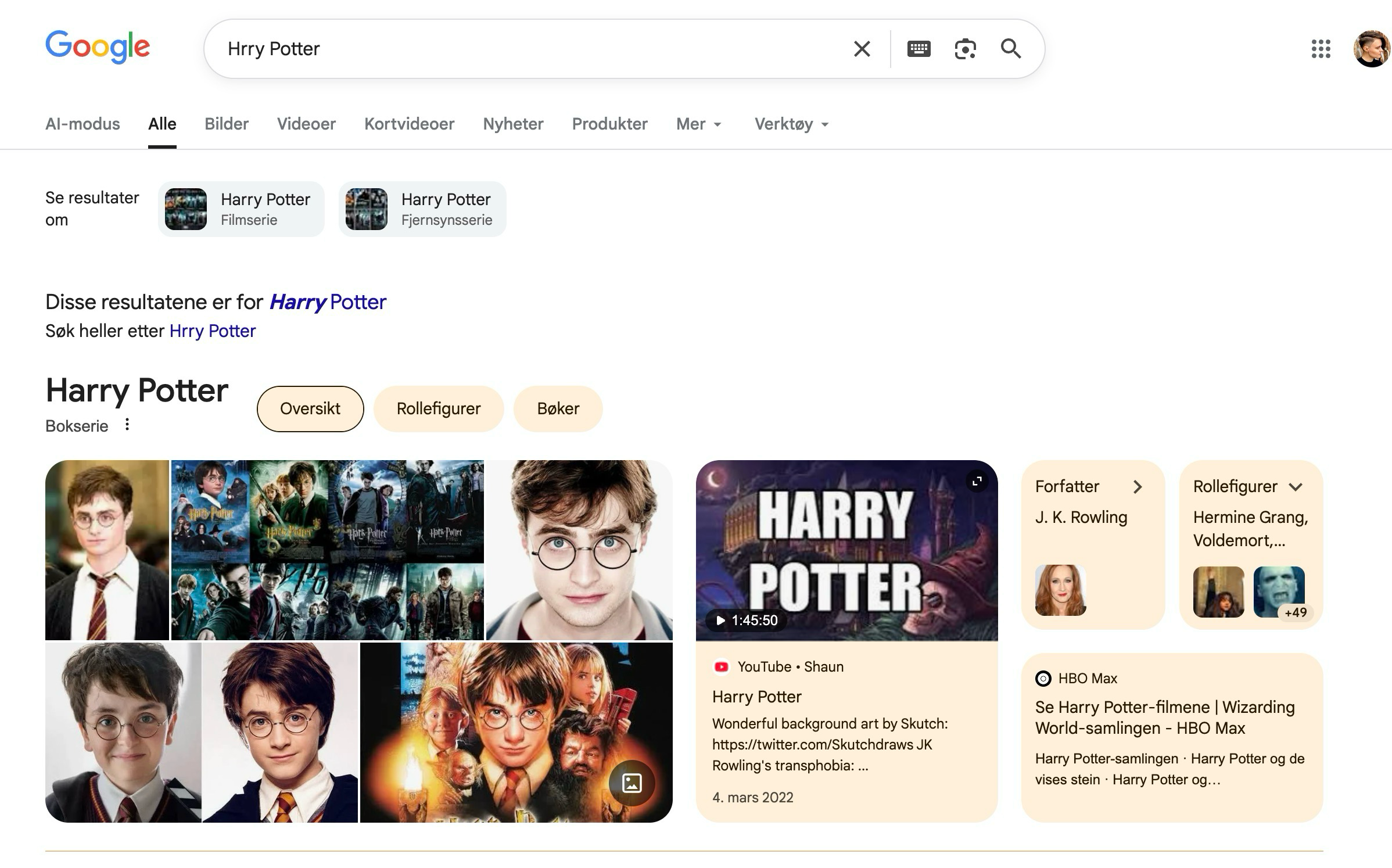
Assosiasjoner bygges inn
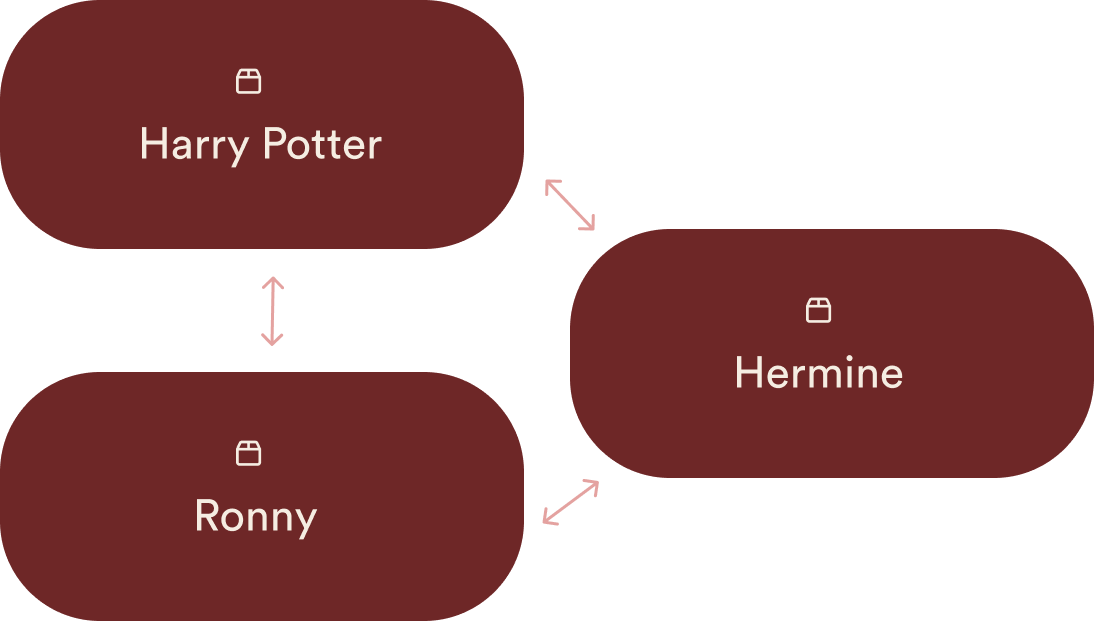
Når man bygger "embeddings" av ord, så vil ord som ofte nevnes sammen bli sterkere assosiert.
Dermed vil "Ronny" og "Hermine" være to andre konsepter som er sterkt assosiert med "Harry Potter".
I tillegg vil ord som "J.K. Rowling", "Trollmann", "Galtvort", "Fantasy" også bli assosiert med Harry Potter.

PS: Anbefaler deg å sjekke ut denne gode artikkelen fra Towards Data Science som eksemplene er sterkt inspirert av.
Regne på ord?
Full disclosure: Matematikk er definitivt ikke mitt fagfelt, selv om jeg synes dette er artig å lære om.
Likevel må jeg til slutt nevne at et artig konsept med embeddings, er at du kan begynne å regne på ord. For det er jo bare matematiske verdier, tross alt.

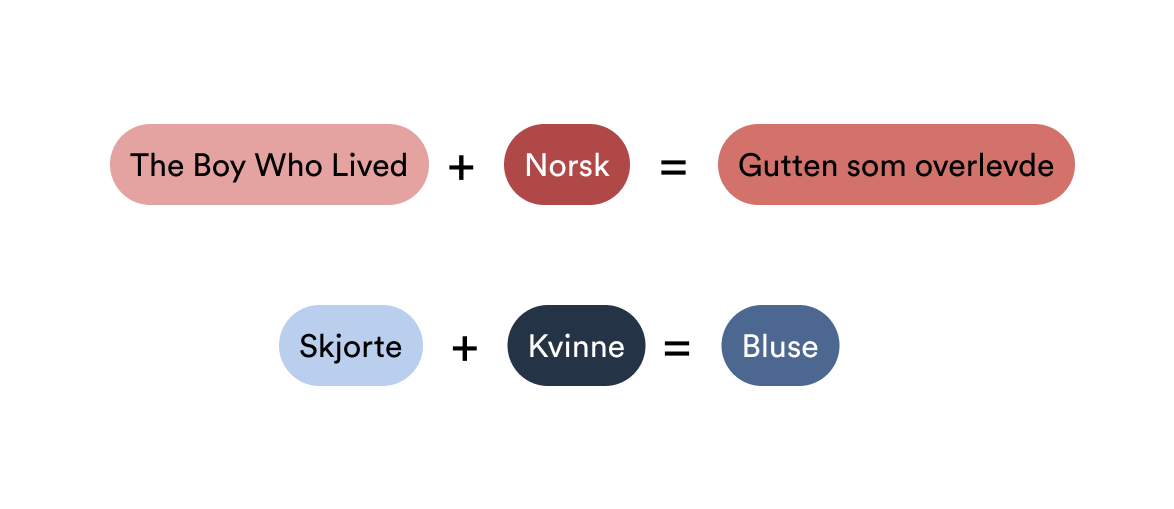
For eksempel: Om du plusser "The Boy Who Lived" med "Norsk" kan du få resultatet "Gutten som overlevde". Artig, eller hva?
Men det er ingen garanti for bra resultater alene. Dessuten vil fort fordommer og stereotyper snike seg inn.
Det er ikke AI-modellens skyld, den reflekterer bare dataen den er trent opp på.
Uansett er det er problem som vi kommer tilbake til.
Hvorfor er embeddings så ekstremt nyttig?
Mulighet til å lagre enormt mye informasjon på lite plass
Embeddings gjør det mulig å lagre store mengder informasjon på en mer effektiv måte.
Gjør det ekstremt raskt å finne informasjon
For oss mennesker gir det ikke mye mening å finne informasjon gjennom tallverdier.
Men for Google som lynraskt må forstå hva du søker på for å deretter lynraskt hente ut relevante resultater – er dette genialt.
Forstå intensjonen og betydningen av informasjonen, ikke bare lese ord
Det å bygge chatboter før i tiden var en ganske krevende manuell prosess der du måtte sette opp regler som "Hvis dette ordet nevnes, si dette" osv. Og resultatet ble sjeldent bra.
ChatGPT og andre språkmodeller fungerer på en helt annen måte. Den oversetter ordene du sier til vektorer, altså tallverdier, som gjør at den på en helt annen måte faktisk kan forstå akkurat hva du mener.
Selv når du kommer hjem drita fra byen og starter en eksistensiell samtale med ChatGPT kl. 4 om natte. Den tilgir dine skriveleifer.
Revolusjonen: Språkmodeller som ChatGPT snur alt på hodet
Alt det vi har snakket om hittil er ikke noe nytt. Kunstig intelligens og embeddings har vi hatt i mange mange år.
Å få en AI-modell til å fullføre en setning, gjennom at den bruker statistikk til å "gjette" hva som var de mest sannsynlige ordene som fulgte etter første del har vi også hatt i mange år.
Men da ChatGPT ble lansert i 2022, med en språkmodell som du faktisk kunne holde en samtale med – uten at den mistet tråden? Det forandret alt.
Verden i 2022
La oss stoppe opp litt, og diskutere gode gamle dager.
Om du før ville finne noe informasjon var du dømt til å gjøre følgende:
- Gå inn i nettsiden eller systemet der informasjonen ligger, og trykk deg rundt i brukergrensesnittet til du finner informasjonen
- Eventuelt: Bruk Google til å finne nettsider som kan ha informasjonen. Trykk deg inn på lenkene og trykk deg rundt til du finner informasjonen.
Massevis av trykk og sløsing av tid, med andre ord.
Verden nå i 2025
Vi er bare såvidt i gang med å virkelig utnytte potensialet i AI-modellene.
Men om du tar i bruk ChatGPT som finnes, kan prosessen for å finne informasjon se HELT annerledes ut.
- Istedenfor å måtte trykke deg rundt i nettleseren, kan du nå bare forklare – muntlig eller skriftlig – en AI-modell hva slags informasjon du trenger.
- AI-modellen vil oversette ordene dine til tallverdier og deretter predikere hva som er sannsynligvis er et bra svar på det du etterspør.
- Så gir den deg svaret – formulert på et naturlig språk.
Det som før kunne ta en time, kan nå ta sekunder.
Problemet: Språkmodellene løser ikke problemet alene – og kan lage mange nye problemer
Ikke til å stole på
Til tross for at språkmodeller som ChatGPT er revolusjonerende, har de én fundamental svakhet: De kan ikke skille mellom fakta og fiksjon.
Når du spør ChatGPT om noe, genererer den ikke et svar basert på å "slå opp" informasjon – den genererer ord basert på statistisk sannsynlighet fra treningsdataene sine.
Det er litt som å spørre noen som har lest tusenvis av bøker om et tema, men ikke husker nøyaktig hvilken bok som sa hva. Svaret høres intelligent ut, men kan være helt feil.
Dette kalles hallusinasjoner – når AI-en med stor selvtillit presenterer informasjon som høres troverdig ut, men som er helt eller delvis oppdiktet.
Utdatert informasjon
AI-modellene har lært mønstre fra enorme mengder tekst, og lagret denne 'kunnskapen' som milliarder av numeriske verdier inne i modellen.
Men denne kunnskapen er statisk – den vet ikke noe om hva som skjedde etter den ble trent, og den kan ikke skille mellom fakta den lærte og feil den plukket opp.
Reflekterer ofte unyttige eller skadelige fordommer
AI-modeller lærer fra tekst som er skrevet av mennesker – og mennesker har fordommer. Når milliarder av nettsider, bøker og artikler brukes som treningsdata, lærer modellen ikke bare fakta og språk, men også stereotype tankemønstre, skjeve representasjoner og kulturelle bias som ligger i dataene.
Konkrete eksempler:
- Profesjoner og kjønn: Spør en AI om "en sykepleier" og den assosierer ofte med kvinnelige pronomen. Spør om "en ingeniør" og den tenker oftere maskulint.
- Geografisk bias: AI-modeller er tungt trent på engelskspråklig, vestlig innhold. Det betyr at de ofte gir svar som reflekterer amerikanske eller europeiske perspektiver, selv når du spør på norsk om norske forhold.
- Historisk skjevhet: Fordi mye av treningsdataene inneholder historiske tekster, kan AI-en gjenskape utdaterte holdninger eller problematiske karakteriseringer.
- Sosiokulturelle antagelser: AI-en kan gjøre antagelser om "normale" familiestrukturer, religioner, eller livsstiler basert på hva som var mest representert i treningsdataene.
Hvorfor dette er problematisk: Når du bruker en generisk AI-modell til å generere kundeservice-svar, markedsføringstekster eller produktbeskrivelser, risikerer du at disse fordommene siver inn i kommunikasjonen din – uten at du er klar over det.
Gir ofte middelmådige resultater
ChatGPT og lignende modeller er trent til å være generalistiske – de skal kunne svare på alt fra oppskrifter til fysikk til programmering. Men nettopp fordi de prøver å være gode på alt, blir de sjelden eksepsjonelle på noe spesifikt.
Hvorfor dette skjer:
Når du ber en generisk AI om å skrive produkttekst, generere FAQ-svar, eller lage markedsføringsinnhold, har den ikke:
- Din merkevare-stemme – den lager generisk innhold som høres ut som alle andre
- Dine spesifikke produktdetaljer – den gjetter på funksjoner og fordeler
- Din bransjekunnskap – den bruker klisjeer i stedet for genuine innsikter
- Dine kunders faktiske spørsmål – den lager "vanlige" spørsmål basert på hva som er vanlig på nettet generelt
Tidkrevende å få riktig svar
Det finnes massevis av teknikker og buzzord for å produsere bra resultater likevel. Prompt-engineering eller context engineering.
Men helt ærlig? Med mindre du er skikkelig nerdete som meg – så orker ikke de fleste mennesker å sette seg inn i alt dette.
Dessuten er det i mange tilfeller mer tidkrevende å få til å bruke en LLM-modell riktig, enn det hadde vært å bare gjøre det selv på "gamlemåten".
Nøkkelen til gode resultater? Strukturert innhold
Her er den gode nyheten: Du trenger ikke bli en prompt-engineering-ekspert. Du trenger ikke bruke timer på å finpusse AI-instruksjoner hver gang. Og du trenger ikke akseptere generiske, middelmådige resultater.
Nøkkelen ligger i å gi AI-en tilgang til riktig informasjon på riktig måte.
Når AI-modeller får tilgang til strukturert innhold – innhold organisert på en måte maskiner faktisk forstår – endrer spillereglene seg fundamentalt. I stedet for å "gjette" basert på gammel treningsdata som ikke er relevant, kan AI-en faktisk slå opp i ditt oppdaterte, verifiserte innhold.
Eksempel: En AI-assistent som faktisk kjenner bedriften din
La oss si at du jobber i en organisasjon med tusenvis av dokumenter, retningslinjer, møtereferater og rapporter spredt utover ulike systemer. Når noen nye starter, bruker de gjerne uker på å finne ut av hvor ting er og hvordan ting gjøres.
Men hvis alt dette innholdet var strukturert – organisert med metadata om tema, dato, forfatter, relevans – kunne en AI-assistent:
- Svare på spørsmål som "Hva er vår policy på hjemmekontor?" ved å hente fram den nyeste, korrekte informasjonen fra riktig dokument
- Oppsummere alle møtereferater fra siste kvartal som handler om et spesifikt prosjekt
- Foreslå relevante personer å snakke med basert på deres tidligere arbeid og kompetanse
- Skrive utkast til rapporter basert på tidligere suksessfulle rapporter fra lignende prosjekter
Og det beste? Den gjør dette på sekunder, med informasjon den vet er riktig, fordi den henter det direkte fra deres egne strukturerte kilder.
Fra generisk til skreddersydd
Her er forskjellen:
Uten strukturert innhold: Du: "Skriv en e-post til kunde X om forsinkelsen i prosjektet." AI: Skriver en generisk, kjedelig unnskyldnings-e-post som høres ut som den er skrevet av en robot.
Med strukturert innhold: Du: "Skriv en e-post til kunde X om forsinkelsen i prosjektet." AI: Henter informasjon om kunde X, deres kommunikasjonsstil, tidligere e-poster du har sendt dem, status på prosjektet fra prosjektdatabasen, og skriver en e-post som både er ærlig, profesjonell og høres ut som deg.
Det er forskjellen mellom en generisk robotstemme og en assistent som faktisk kjenner deg og virksomheten din.
Strukturert innhold + AI = Magien skjer
Her er noen konkrete eksempler på hva som blir mulig når du kombinerer strukturert innhold med AI:
For en nettbutikk:
- AI kan automatisk skrive produktbeskrivelser som matcher din tone of voice, basert på strukturert produktdata
- Kundeservice kan få AI-drevne svar som tar utgangspunkt i faktiske produktspesifikasjoner, leveringstider og retningslinjer
- Personaliserte produktanbefalinger basert på både kundens historikk og produktenes strukturerte attributter
For en organisasjon:
- Automatisk generering av rapporter basert på strukturerte data fra prosjekter og aktiviteter
- AI som hjelper deg å finne riktig person å spørre om noe, basert på strukturert informasjon om ansattes kompetanse og tidligere arbeid
- Intelligent søk som forstår hva du egentlig lurer på og henter fram relevant informasjon fra hele organisasjonens innholdsbase
For et byrå (som oss):
- AI som hjelper oss å lage tilbud ved å hente informasjon fra tidligere suksessfulle prosjekter
- Automatisk generering av case-studier basert på strukturerte prosjektdata
- Presentasjoner som bygger seg selv basert på klientens bransje, utfordringer og våre relevante erfaringer
MCP-servere: Når AI får superkrefter
Det aller nyeste (og kanskje kuleste) er MCP-servere (Model Context Protocol). Dette er i bunn og grunn en standardisert måte for AI-modeller å snakke med dine systemer og databaser på.
Tenk på det som om AI-en får en direkte telefonlinje til alle dine systemer, i stedet for at du må kopiere og lime informasjon fram og tilbake.
Med MCP kan AI-en for eksempel:
- Søke i Google Drive etter relevante dokumenter
- Hente informasjon fra Notion-databasen din
- Lese kalenderen din for å finne ledig tid
- Hente data fra CRM-systemet deres
- Og mye, mye mer
Alt dette – uten at du manuelt må hente fram informasjonen og mate den til AI-en. Den gjør det selv, på sekunder, basert på hva du spør om.
Men gjett tre ganger hva som må være på plass for at dette skal fungere godt?
Nettopp. Strukturert innhold.


Nivå 5: Tenk større – hele verdens innhold strukturert og tilgjengelig
Til nå har vi snakket om hvordan du kan strukturere ditt innhold. Men la oss zoome ut litt og se på det virkelig store bildet.
Hva hvis hele internett var strukturert som et bibliotek?
Drømmen: Et internett maskiner faktisk forstår
I dag er internett stort sett bygget for mennesker å lese. Nettsider er fylt med tekst, bilder og videoer som ser fine ut i en nettleser, men som er fullstendig kaos for maskiner.
Når Google prøver å forstå hva en nettside handler om, må den i bunn og grunn "gjette" basert på overskrifter, nøkkelord og lenker. Det fungerer okei, men det er langt fra optimalt.
Forestill deg i stedet et internett hvor:
- Hver nettside ikke bare viser informasjon, men erklærer hva den inneholder på en måte maskiner forstår
- En produktside sier eksplisitt: "Dette er et produkt. Det heter X. Det koster Y. Det har disse funksjonene. Det tilhører denne kategorien."
- En personsside sier: "Dette er en person. Hun heter Z. Hun jobber som A. Hun har skrevet disse artiklene. Hun kjenner disse personene."
- En oppskriftsside sier: "Dette er en oppskrift. Den tar 30 minutter. Den krever disse ingrediensene. Den gir 4 porsjoner."
Dette er ikke science fiction. Det finnes allerede.
Schema.org: Internettets felles språk
I 2011 samlet Google, Microsoft, Yahoo og Yandex seg for å lage noe revolusjonerende: Schema.org – et felles vokabular for å beskrive innhold på nettet.
Tenk på det som et universelt biblioteksystem, men for hele internett.
Med Schema.org kan nettsteder legge til "strukturerte data" – usynlig informasjon for mennesker, men krystallklar for maskiner – som forklarer hva innholdet faktisk er.
Et enkelt eksempel:
Når du søker på "sjokoladekake oppskrift" på Google, får du ofte ikke bare lenker – du får oppskrifter presentert med bilde, rating, tid og ingredienser direkte i søkeresultatet.
Hvordan vet Google alt dette? Fordi nettsiden har brukt malen dra Schema.org til å strukturere informasjonen slik:
Dette er strukturert innhold for nettet. Og det endrer alt.
Hvordan strukturert data på nettet endrer spillet
1. Søk blir smartere
Google kan nå gi deg svar i stedet for bare lenker. Spør "hvor gammel er Eiffeltårnet?" og du får svaret direkte, fordi nettsteder har strukturert denne informasjonen med Schema.org.
2. AI-modeller får tilgang til faktisk kunnskap
Når AI-modeller kan lese strukturerte data fra nettet – ikke bare gjette fra tekst – blir de plutselig langt mer pålitelige.
ChatGPT Search, Perplexity, Google AI Overviews – alle disse bruker strukturert data fra nettet for å gi bedre, mer verifiserbare svar.
3. Informasjon kan flyte fritt mellom systemer
Med strukturerte data kan:
- Din kalender hente arrangement direkte fra nettsider som annonserer dem
- Handlelisteappen din hente ingredienser fra oppskriften du fant
- Kartet ditt vise åpningstider, adresse og telefonnummer automatisk fra bedriftens nettside
- Smarte høyttalere svare på komplekse spørsmål ved å kombinere strukturert data fra flere kilder
4. Nye tjenester kan bygges på andres innhold
Akkurat som biblioteket kunne dele sine strukturerte data med leseappen, kan nettsteder dele sine strukturerte data med hele verden.
Dette skaper et økosystem av innovasjon. Noen lager innholdet. Andre bygger smarte tjenester på toppen av det.
Men vi er bare i starten
Til tross for at Schema.org eksisterer, bruker fortsatt altfor få nettsteder det. De aller fleste nettsider er fortsatt "verdens verste bibliotek" – full av informasjon, men uten system.
Problemet:
De fleste nettsteder er bygget med systemer (CMS-er) som gjør det vanskelig å strukturere innhold. WordPress, Wix, Squarespace – de er laget for at innhold skal se pent ut, ikke for at maskiner skal forstå det.
Det krever ekstra arbeid, teknisk kunnskap, og vedlikehold å legge til strukturerte data. Og de fleste gidder rett og slett ikke.
Men dette holder på å endre seg. Raskt.


Den nye virkeligheten: AI krever strukturert innhold for å se deg
Her er den brutale sannheten: I fremtiden vil nettsider som ikke har strukturert innhold bli usynlige.
Ikke for mennesker – de kan fortsatt besøke siden direkte.
Men for AI-systemer? De vil prioritere nettsider som eksplisitt forteller hva de inneholder.
Tenk på det slik:
Før (Google-æraen):
- Google "gjetter" hva siden din handler om basert på ord og lenker
- Alle konkurrerer om å rangere på side 1
- SEO-eksperter optimaliserer for søkemotorer
Nå (AI-æraen):
- AI-systemer velger én kilde å svare fra
- Ikke lenger 10 lenker – ett generert svar
- Nettsider med strukturerte data siteres. Nettsider uten ignoreres.
ChatGPT Search, Google AI Overviews, Perplexity – de prioriterer alle innhold som er strukturert og verifiserbart.
Eksempel:
Spør AI: "Hva er den beste italienske restauranten i Oslo?"
- Restaurant A har strukturert data: navn, rating (4.8 fra 300 anmeldelser), meny, priser, åpningstider, adresse.
- Restaurant B har bare tekst på nettsiden: "Vi er en koselig italiensk restaurant..."
Gjett hvilken AI-en kommer til å anbefale?
Den store visjonen: Det semantiske nettet
Det finnes en visjon – opprinnelig fra Tim Berners-Lee, han som oppfant World Wide Web – om et "Semantic Web".
Et nett hvor maskiner ikke bare viser informasjon, men forstår den. Hvor data ikke er fanget inne i nettsider, men flyter fritt mellom systemer og applikasjoner.
🤯 Tenk på mulighetene
For helse:
- Pasientjournaler fra ulike sykehus kan snakke sammen
- Legemiddelinformasjon kan automatisk sjekkes mot allergier og interaksjoner
- Forskningsdata fra hele verden kan kombineres for å finne nye behandlinger
For utdanning:
- Læringsmateriell fra ulike kilder kan automatisk tilpasses hver enkelt elev
- Kunnskapsgrafer kan vise sammenhenger mellom konsepter på tvers av fag
- Eksamenssystemer kan automatisk evaluere forståelse, ikke bare hukommelse
For næringsliv:
- Forretningsdata kan deles trygt mellom organisasjoner
- AI-assistenter kan automatisk finne, sammenligne og analysere leverandører, produkter og tjenester
- Nye forretningsmodeller kan bygges på strukturerte data fra mange kilder
For samfunnet:
- Offentlige registre kan snakke sammen uten byråkratisk heft
- Demokratiske beslutninger kan tas basert på faktisk data, ikke magefølelse
- Journalister og faktasjekkere kan verifisere påstander automatisk
Fra teori til praksis: Det skjer allerede
Dette høres kanskje ut som sci-fi, men mye av dette er allerede virkelighet:
Knowledge Graphs: Google, Facebook, LinkedIn – de har alle bygget gigantiske "kunnskapsgrafer" som kobler sammen mennesker, steder, konsepter og fakta på strukturerte måter.
Når du søker på "Leonardo DiCaprio filmer", gir Google deg ikke bare lenker – det gir deg en liste av filmer, fordi de vet at Leonardo DiCaprio er en person, som har spilt i disse filmene, som ble laget disse årene.
Linked Open Data: Offentlige institusjoner, universiteter og forskningssentre publiserer stadig mer data som "Linked Open Data" – strukturert informasjon som er fritt tilgjengelig og kan kobles sammen.
Wikidata alene har over 100 millioner strukturerte datapunkter om alt fra personer til planeter.
AI-drevne søkemotorer: Perplexity, ChatGPT Search, Google AI Overviews – alle bruker strukturert data fra nettet for å gi mer presise, verifiserbare svar.
MCP-servere og AI-integrasjoner: Som vi nevnte tidligere – systemer som Notion, Google Drive, Asana kan nå snakke direkte med AI-modeller gjennom standardiserte protokoller.
Men for at dette skal fungere optimalt? Innholdet må være strukturert.
Den ubehagelige sannheten
Nettsteder som ikke strukturerer innholdet sitt vil gradvis bli usynlige i AI-tidsalderen.
Ikke fordi noen sensurerer dem. Men fordi AI-systemer enkelt og greit velger å bruke innhold som er lettere å forstå og verifisere.
Tenk på det som evolusjon:
- År 2000: Nettsteder uten HTML er usynlige for nettlesere
- År 2010: Nettsteder uten mobiloptimalisering mister besøkende
- År 2020: Nettsteder uten HTTPS blir merket som "usikre"
- År 2025: Nettsteder uten strukturert innhold blir ignorert av AI
De som strukturerer innholdet sitt nå – de får førstemoversfordelen. De blir kildene AI-er siterer. De blir de autoritative stemmene i sin bransje.
De som venter? De må ta igjen konkurrentene senere, med høyere kostnad og mindre innflytelse.
Ditt valg: Bli sett eller bli glemt
Du har to veier fremover:
Vei 1: Status quo
- Fortsett med innhold som bare er pent for mennesker å se på
- Håp at Google og AI-systemer "gjetter" riktig om hva siden din handler om
- Se konkurrentene gradvis bli mer synlige enn deg
- Bli hengende etter i AI-revolusjonen
Vei 2: Strukturer innholdet ditt
- Bygg innhold på en måte som både mennesker og maskiner forstår
- Bli en autoritativ kilde som AI-systemer siterer
- Få muligheten til å gjenbruke innholdet ditt på utallige nye måter
- Vær klar for fremtiden, uansett hvilke nye AI-verktøy som kommer
Valget er egentlig ganske enkelt.
Men det krever at du tenker annerledes om innhold. Ikke som "sider på en nettside", men som strukturert kunnskap som kan leve, vokse og brukes på utallige måter.
Det er der vi kommer inn.


Fremtiden tilhører de som strukturerer innholdet sitt
Vi har snakket om biblioteker, databaser, AI og mye annet rart. Men la oss zoome litt ut og se på det store bildet.
Verden blir mer og mer digital. Informasjon er den nye valutaen. De som kan organisere, strukturere og utnytte informasjon effektivt kommer til å ha et enormt konkurransefortrinn.
Tenk på tech-gigantene – Google, Facebook, Amazon. Hva har de til felles? De sitter på enorme mengder strukturert data om oss, og de vet hvordan de skal bruke den.
Men nå – med moderne verktøy, headless CMS-er, og AI-assistenter – er denne superkraften ikke lenger bare forbeholdt gigantene.
Du kan også bygge ditt eget lille innholdsunivers. Strukturert. Gjenbrukbart. Kraftfullt.
Og når AI blir bedre og bedre (og det blir den), vil verdien av ditt eget strukturerte innhold bare øke.
De som fortsetter å bygge nettsider som "verdens verste bibliotek" – med informasjon spredt utover uten system eller struktur – kommer til å bli hengende etter. De vil fortsette å bruke utallige timer på å lete, kopiere, lime, oppdatere og frustrere seg.
Men de som tar seg bryet med å strukturere? De får superkrefter. De kan bygge nye løsninger på rekordtid. De kan personalisere opplevelser. De kan automatisere det kjedelige. De kan bruke AI på måter som faktisk gir mening.
De kommer til å vinne fremtiden.
Vil du ha superkrefter?
Vi i Kult Byrå brenner for strukturert innhold.
Vi har bygget utallige løsninger der strukturert innhold er selve fundamentet – fra presentasjonsgeneratorer til rapportverktøy til komplekse nettsider som lever og puster i takt med organisasjonens behov.
Og vi ser hver eneste dag hvilken forskjell det gjør. For redaktørene som plutselig får frihet til å publisere innhold overalt uten å måtte vente på utviklere. For organisasjoner som kan lansere nye tjenester på brøkdelen av tiden. For bedrifter som kan ta datadrevne beslutninger fordi informasjonen deres faktisk er strukturert nok til å analysere.
Er du mer nysgjerrig? Ta kontakt eller gå enda mer i dybden på alle mulighetene.
Velkommen til fremtiden. Den er strukturert.

Vilde Serina Partapuoli
Kreativ leder
På de fine sommerdagene i 2007 ville du funnet Vilde i en mørk kjeller for å lage sin fjerde fanside for Harry Potter den måneden. Timene har lønnet seg, for nå kan hun trylle med både ord, kode og farger. Som kreativ leder i Kult Byrå er hun glad i å skrive enormt lange blogginnlegg – til tross for at vi lever i en tid med der det sies at hjernene våre er ødelagt av sosiale medier. At du fortsatt er her og ikke har gått videre til å se på katte-videoer eller sjekke værmelding for sjuende gang i dag, tyder på at du enten har en sjelden hjernemutasjon som gjør deg immun mot moderne oppmerksomhetsødeleggelse, eller – (plot twist) – du er faktisk en fullblods nerd som Vilde. I begge tilfeller: våre kondolanser til familie og venner.












Takk 🥳
Vi vil ta kontakt med deg veldig snart.